

#2 Storing financial data
#2 Storing financial data
The most difficult thing predicting financial markets has been collecting and storing financial data
I wanted to get historical daily data so I can start backtesting for algorithmic trading.
I’m collecting data from Yahoo! Finance using a python library called yfinance. Using this library makes it relatively easy, you can collect the last 10 years daily data for AAPL with this simple command:

yfinance.download('AAPL', start='2002-12-01')The Signals universe consists of 5367 Bloomberg tickers, as you will understand downloading data for all these tickers is time expensive, especially if you’re going to run multiple experiments.
Another pain point is to build the mapping between Bloomberg and Yahoo! tickers. Numerai already provides a ticker map file that makes the job easier but is a work in progress, requiring some tweaks and manual work.
After running some experiments — going back and forth checking some tickers that were impossible to download due to mismatches in the mappings, or duplicated rows caused by duplicated tickers in the map file — I decided to invest more time in setting up the database infrastructure to store the data make it easily accessible.
Before jumping to the details, here are some details about the volume of data I’m dealing with:
Total rows: ~15 MM (+15K each week)
Raw columns: 9
I came across this article the week I was implementing the first version of the database infrastructure. I was already thinking about storing the data using a simple approach based on SQLite, so I thought it would be great to use it in combination with Litestream. This way I’ll be able to set up a service in charge of updating the dataset while having it available anywhere, and also offer others the possibility to consume it without bothering about dealing with all the previous mentioned pain points.
After collecting the data and storing everything in SQLite I got a reality check. The most common use case for the database will be to retrieve all the data, and this simple operation took more than 3.5 minutes! I’m sure there are some tweaks I can apply to SQLite to improve the performance but it’s been a big surprise to discover how painfully slow was for the simplest use case.
With the original objective in mind — being able to collect data independently and to distribute it with others — I started to play with Parquet. Long story short, retrieving all the data improved significantly, from 3.5 minutes to 6.8 seconds!
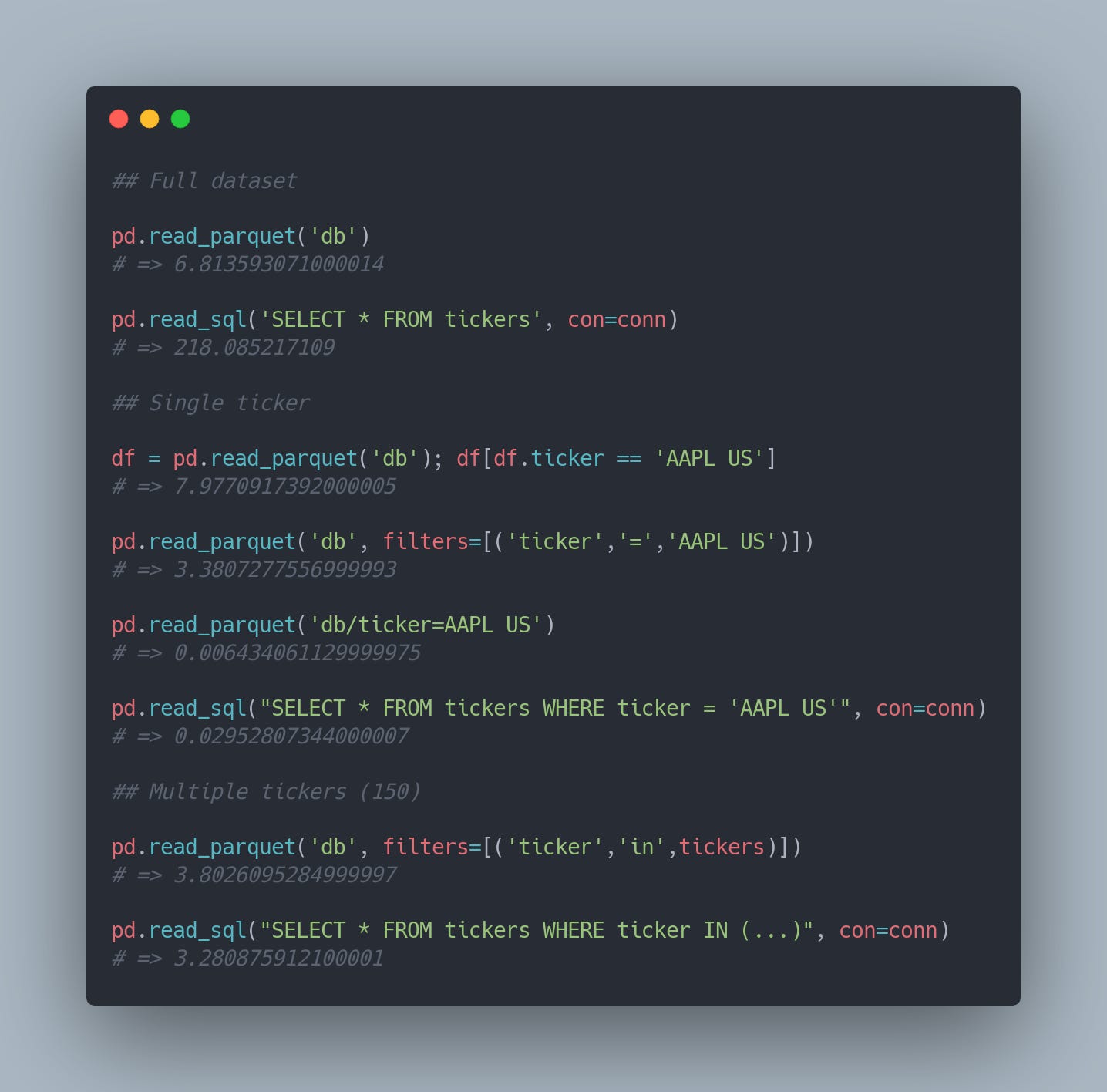
Worth mentioning the disk usage:
SQLite: 2.5GB
Parquet: 544 MB
The comparison is not 100% fair since parquet uses compression, but even using compression is able to retrieve data way faster than SQLite.
I'm planning to publish a library to make the data freely accessible to anyone. But first I'll need to figure out the best approach, would you prefer a library to retrieve data from a public Parquet dataset store in AWS S3, or one to create the dataset locally?
If you have any questions or further suggestions, please leave a comment!
Learning
Jakob Greenfeld wrote an article about the increasing interest in investing
Carlo Lepelaars notebook Getting Started with Numerai Signals: Sentiment Analysis
Suraj Parmar wrote a new article From r/WSB to Numerai Signals
Numerai team published a Signals video playlist
Numerai user hellno initiative on a ticker map supported by the community